From this functionality, the user can use his/her data in the application in order to do new analysis and combine and compare the results with the results obtained with the rest of functionalities.
In order to load the user´s data in the app, the information must be stored in a text file with a CSV format CSV (Coma Separated Value). The head of the file correspond to the name of each column. In this file must exist two fields, one of them called lon and the other lat. In both fields the position is stored. The lon field correspond to the longitude and the lat field to the latitude, both in the WGS84 (EPGS:4326) reference system and in decimal degrees using the coma as decimal separator. Only these fields are required, the rest of the fields correspond with the information that the user wants to analyze.
Here is an example about the csv format ready to be uploaded by the application.

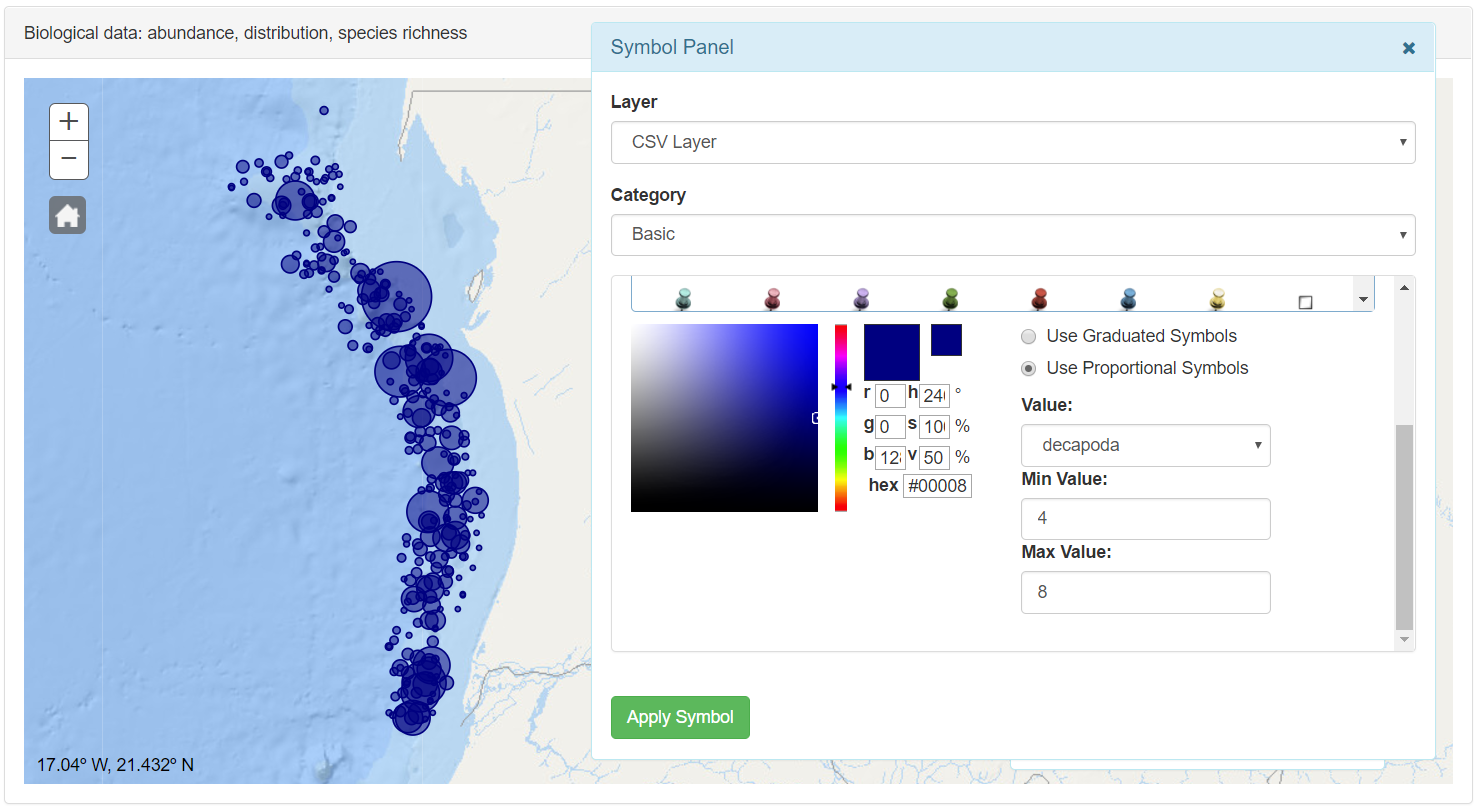
To load the file in the app the user only needs to drag and drop the file over the map and automatically a layer of points is displayed with the samples position of the CSV file. At the same time the Symbol Panel is opened to select the suitable symbology..
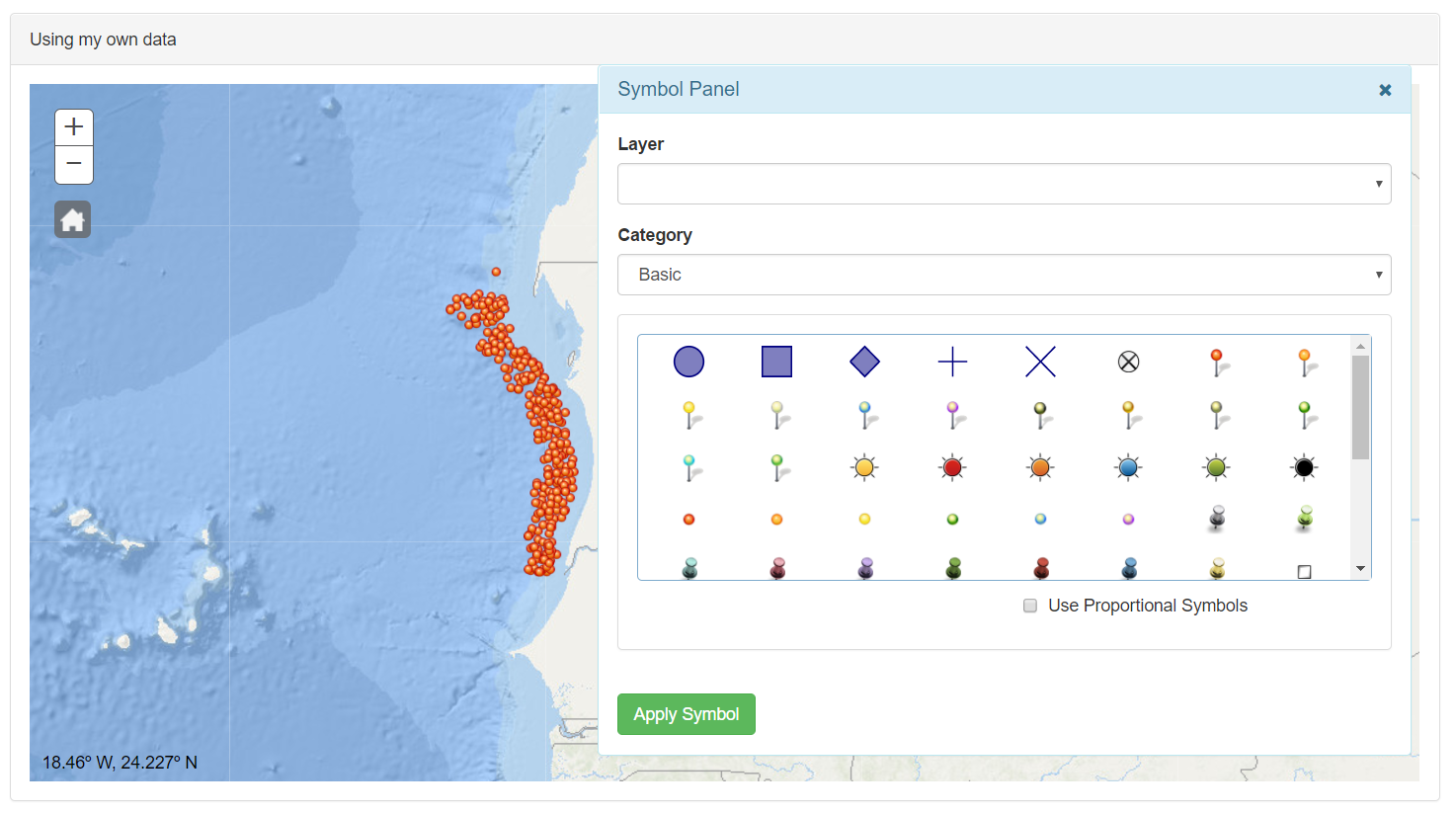
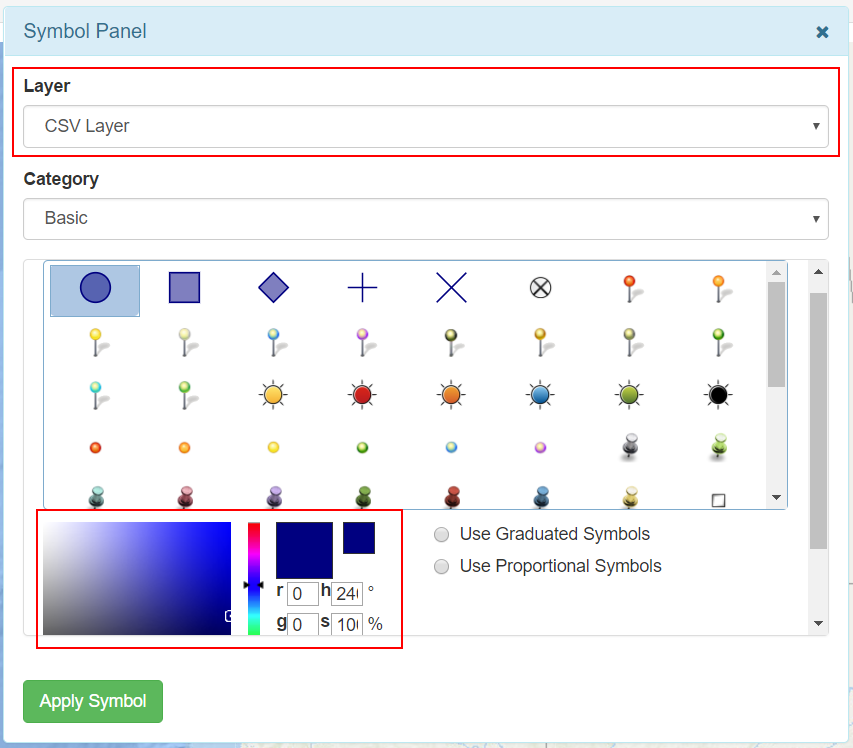
In the Category selector different kind of symbols are accessible. Once time a symbol is selected (click over the symbol), it is possible select the color.
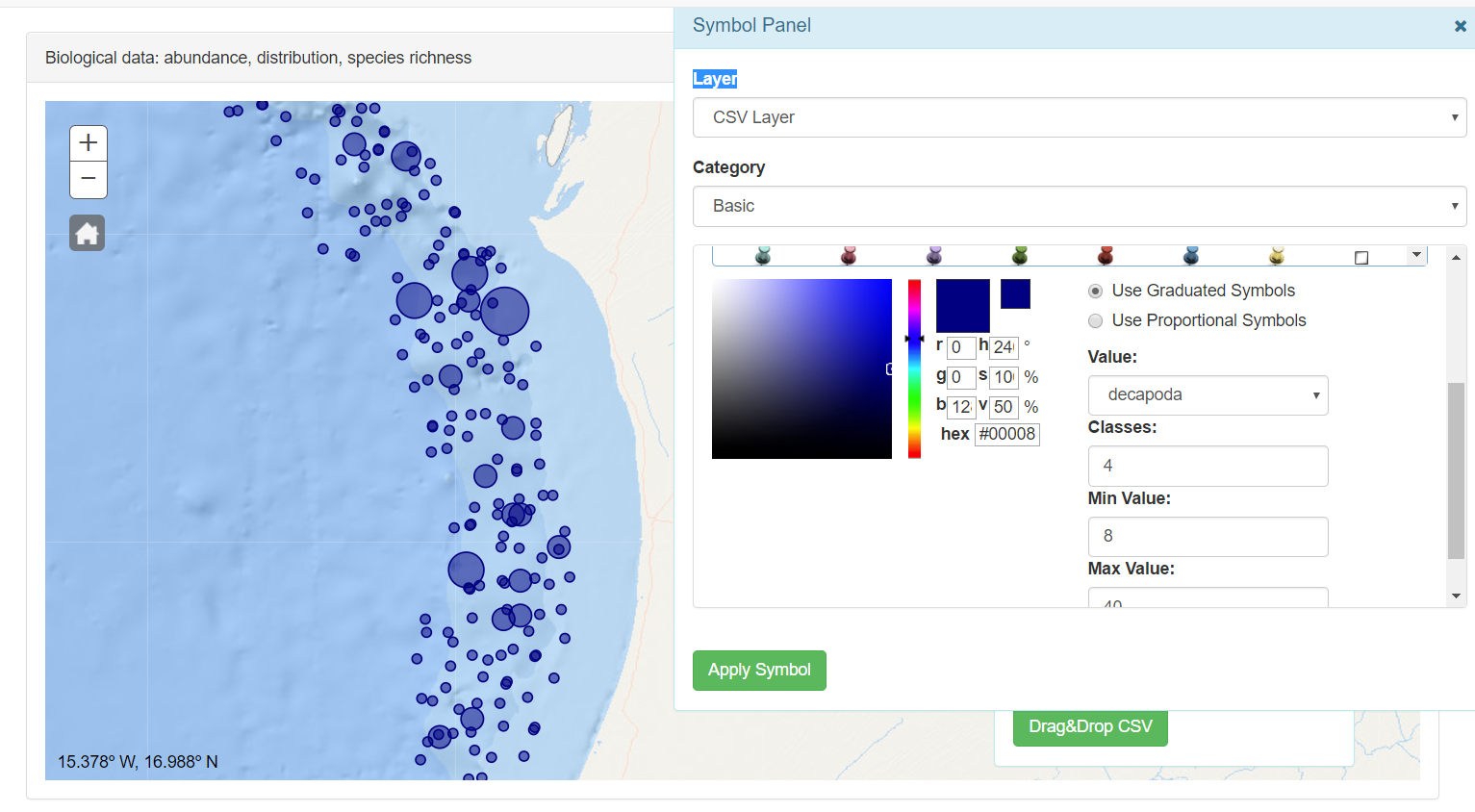
Graduated symbols are used to show a quantitative difference between mapped features by varying the size of symbols. Data is classified into ranges that are each then assigned a symbol size to represent the range. For instance, if your classification scheme has five classes, five different symbol sizes are assigned. The color of the symbols stays the same.
Symbol size is an effective way to represent differences in magnitude of a phenomenon because larger symbols are naturally associated with meaning a greater amount of something. Using graduated symbols gives you a good degree of control over the size of each symbol, because they are not related directly to data values as they are with proportional symbols. This means you can design a set of symbols that have sufficient variation in the size that represents each class of data to make them distinguishable from one another.
In the value selector the field to symbolize is selected. In the classes input the user can write the number of classes to distinguish. With the min value and max value the user can select the min and max value in pixels of the symbol
Proportional symbology is used to show relative differences in quantities among features. Proportional symbology is similar to graduated symbols symbology in that both draw symbols sized relative to the magnitude of a feature attribute. But where graduated symbols distribute features into distinct classes, proportional symbols represent quantitative values as a series of unclassed symbols, sized according to each specific value.
In the value selector the field to symbolize is selected. With the min value and max value the user can select the min and max value in pixels of the symbol
When the user clicks over any entity a popup is displayed. With the arrow button,  the field values are shown for this sample.
the field values are shown for this sample.
Once time the data are loaded the user can use several tools to work with them. To access to these tools only is necessary click the Tools button that is located in the top toolbar. This is the list with the available tools.
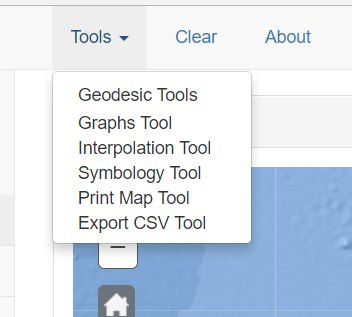
• Geodesic Tools:From this button the Geodesic Tools panel is displayed. This tool was described in the Home Page.
• Graph Tool: This button shows Build Your Graph panel.
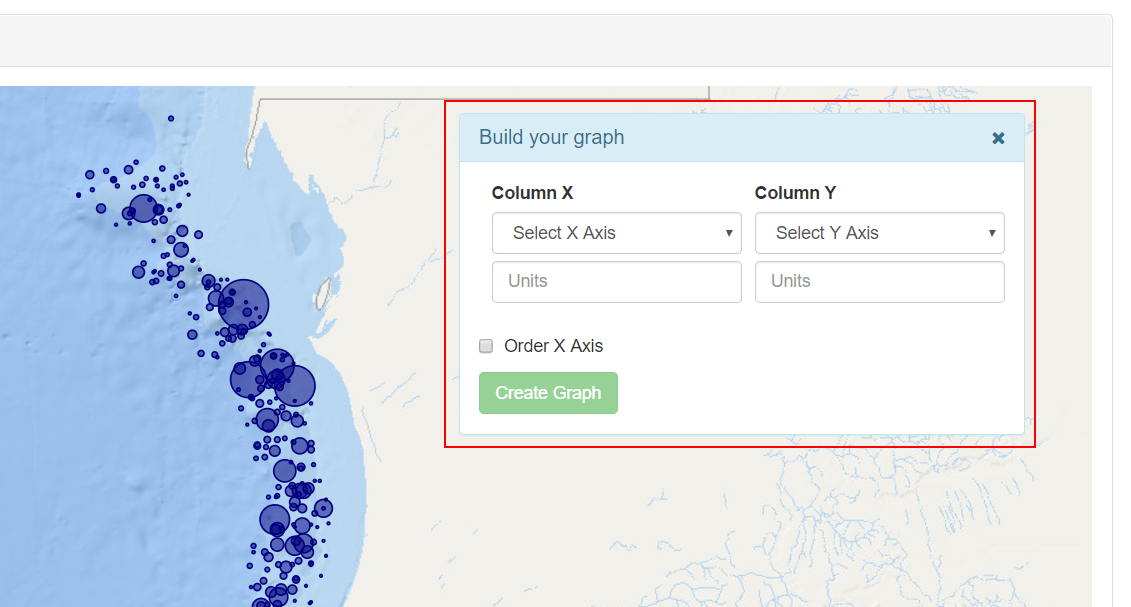
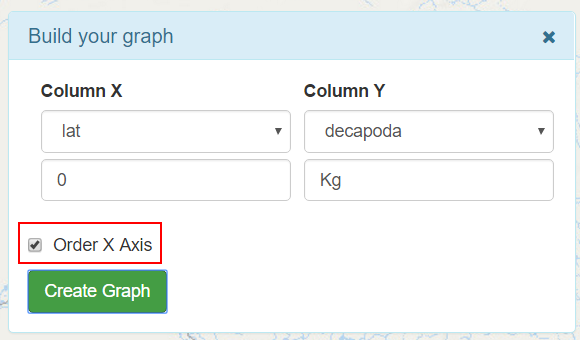
In the Column X and Column Y selectors the user can select any numeric field that exist in the CSV file.
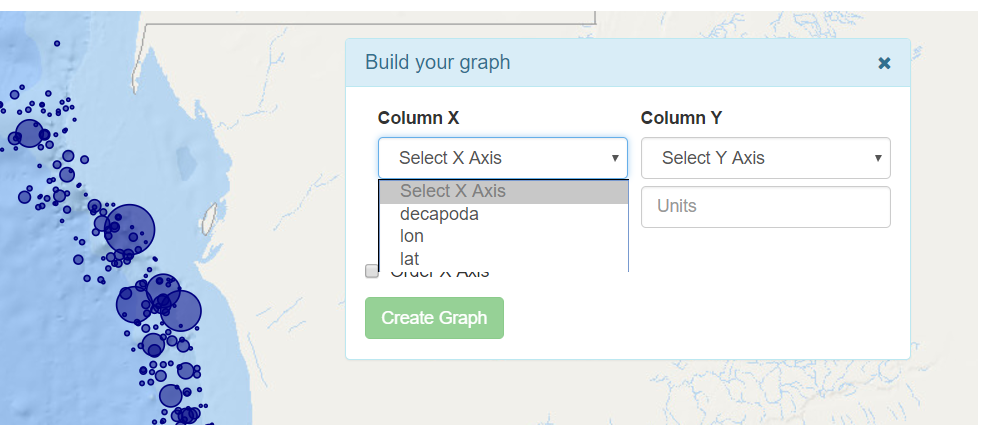
In the Unit inputs, the user can write the units that will be used in the corresponding axis.
The Order X Axis check button, order the values in the x axis from low to high.
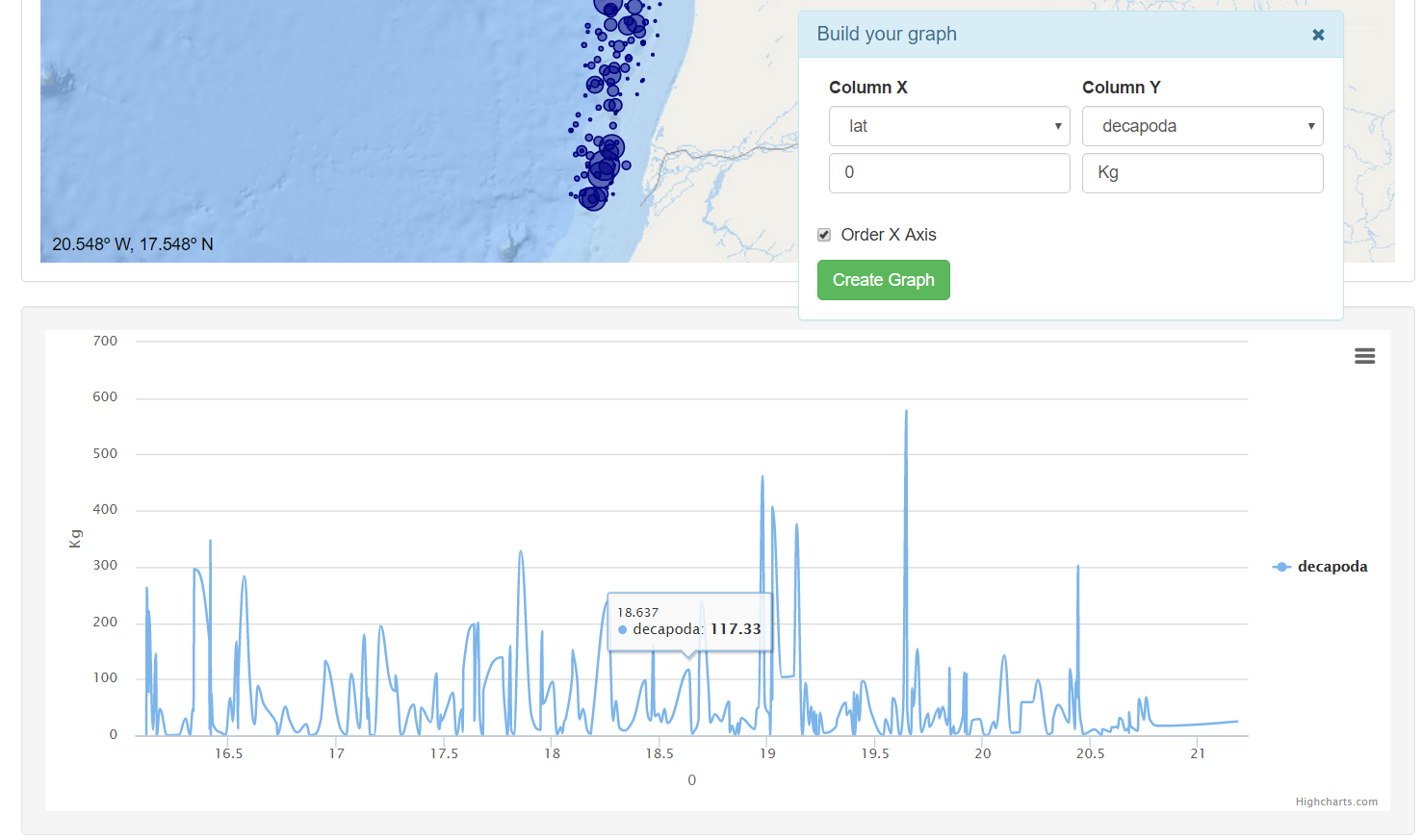
Clicking Create Graph button  shows a graph below the map with the values selected by the user.
shows a graph below the map with the values selected by the user.
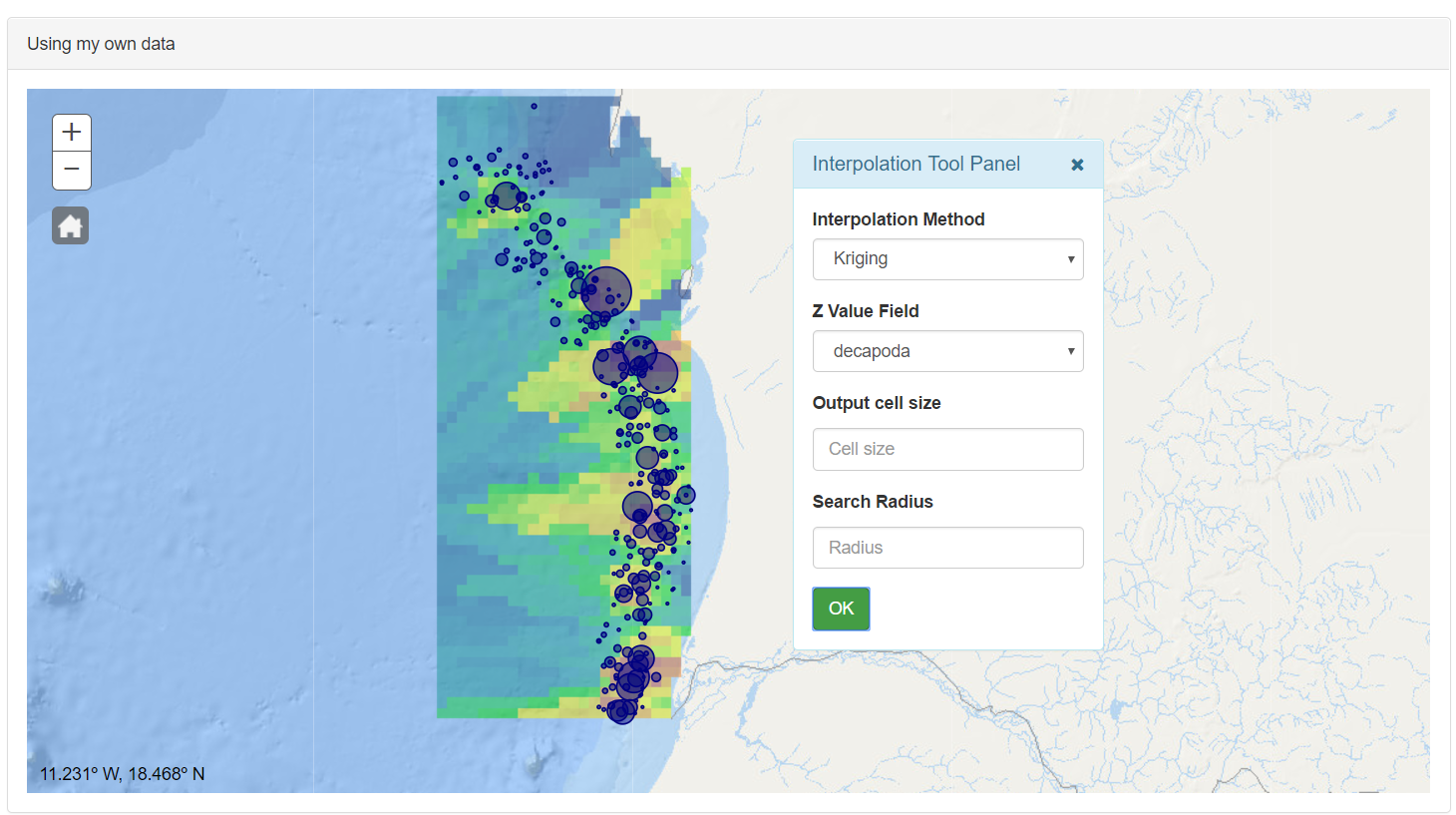
• Interpolation Tool: This button shows the Interpolation Tool panel.
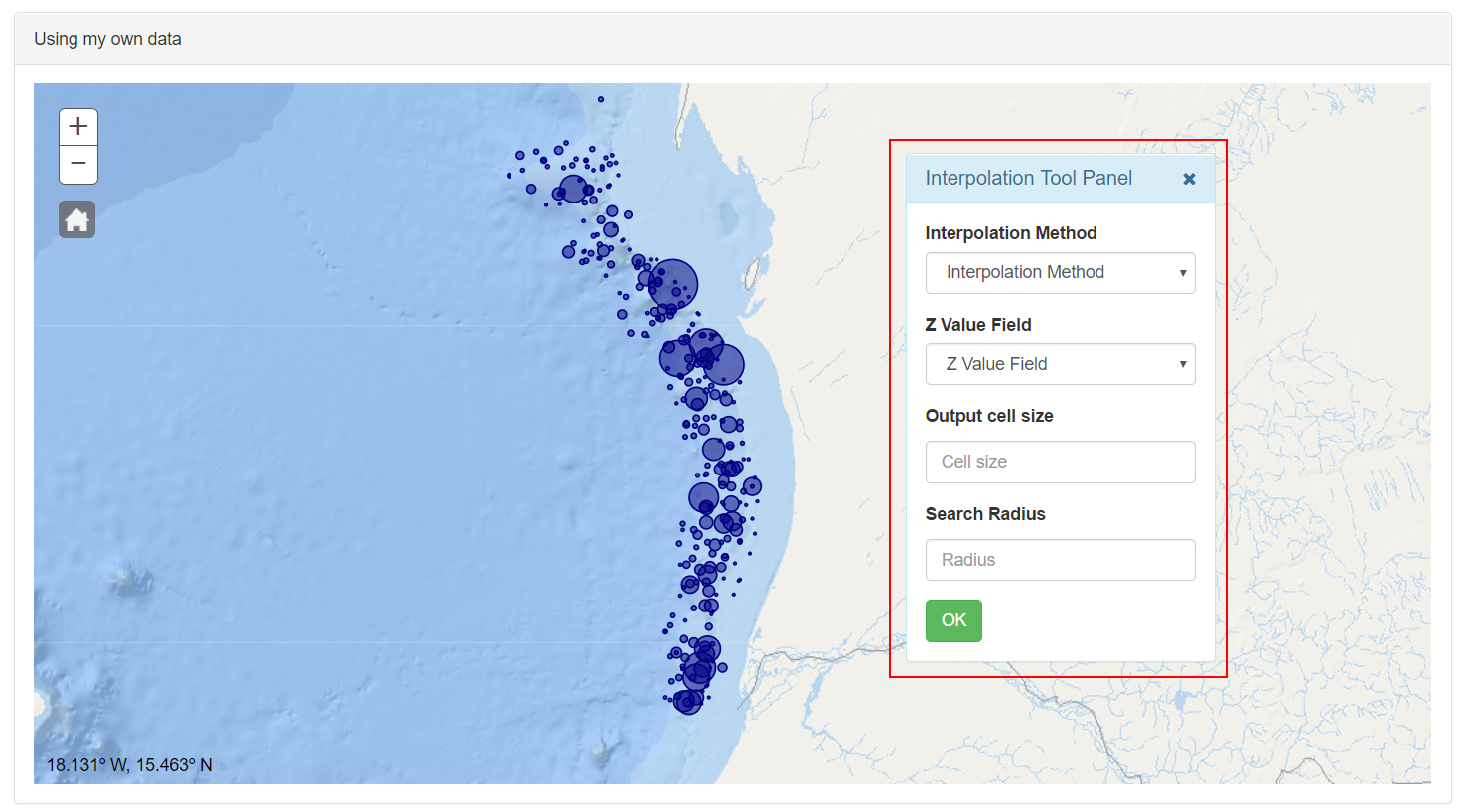
From this panel the user can select their preferences in order to perform an interpolation with the values stored in the CSV file. In the first selector, the method of interpolation is selected. Actually only is available the kriging method. in the z value field selector, the user can select the numeric field target of the interpolation.
The parameter “Output cell size” define the cell size at which the output raster will be created, result of the interpolation. If this input not is fill it, the geoprocessing service will estimate the most appropriate value for the used data.
In the Radius Search input, the user defines which of the input points will be used to interpolate the value for each cell in the output raster.
There are two types of radius classes: RadiusVariable and RadiusFixed. A Variable search radius is used to find a specified number of input sample points for the interpolation. The Fixed type uses a specified fixed distance within which all input points will be used for the interpolation. The Variable type is the default.
RadiusVariable ({numberofPoints}, {maxDistance})
{numberofPoints}—An integer value specifying the number of nearest input sample points to be used to perform interpolation. The default is 12 points.
{maxDistance}—Specifies the distance, in map units, by which to limit the search for the nearest input sample points. The default value is the length of the extent's diagonal.
RadiusFixed ({distance}, {minNumberofPoints})
{distance}—Specifies the distance as a radius within which input sample points will be used to perform the interpolation.
The value of the radius is expressed in map units. The default radius is five times the cell size of the output raster.
{minNumberofPoints}—An integer defining the minimum number of points to be used for interpolation. The default value is 0.
If the required number of points is not found within the specified distance, the search distance will be increased until the specified minimum number of points is found.
When the search radius needs to be increased it is done so until the {minNumberofPoints} fall within that radius, or the extent of the radius crosses the lower (southern) and/or upper (northern) extent of the output raster. No Data is assigned to all locations that do not satisfy the above condition.
If this input not is fill it, the geoprocessing service will estimate the most appropriate value for the used data.
When the user clicks in the ok button, the selected user and the data values are sent to the corresponding geoprocessing service. This geoprocessing send the result as a raster image and this image is loaded on the map.